
Agricultural environments are highly unstructured and variable, posing challenges for robotic manipulation systems that rely solely on visual perception. We present a multi-modal classification framework that fuses audio and visual data to identify which part of a tree—leaf, twig, trunk, or ambient—a robot is in contact with. Evaluated on real robot data containing motor noise and out-of-distribution audio, our approach achieves an F1-score of 0.82. These results demonstrate the promise of audio-visual perception for enabling safe, contact-rich manipulation in challenging agricultural settings.
The following videos demonstrate our model performing real-time classification of contact events with different tree structures. Our multi-modal approach successfully identifies the contacted surface (leaf, twig, or trunk) under varying environmental conditions using both vision and acoustic sensing. These examples illustrate the robustness of our approach across both controlled experimental setups (handheld probe) and deployment on a robotic platform with inherent motion and sensor noise.
Leaf Contact (Robot)
Twig Contact (Robot)
Trunk Contact (Robot)
Leaf Contact (Probe)
Twig Contact (Probe)
Trunk Contact (Probe)
Despite advances in vision-based perception, heavy occlusions and sensor noise in cluttered foliage make contact events hard to perceive. Our key insight is that contact sounds—captured via contact microphones—provide complementary information when vision fails, enabling more robust semantic reasoning about interactions (leaf vs. twig vs. trunk vs. ambient).
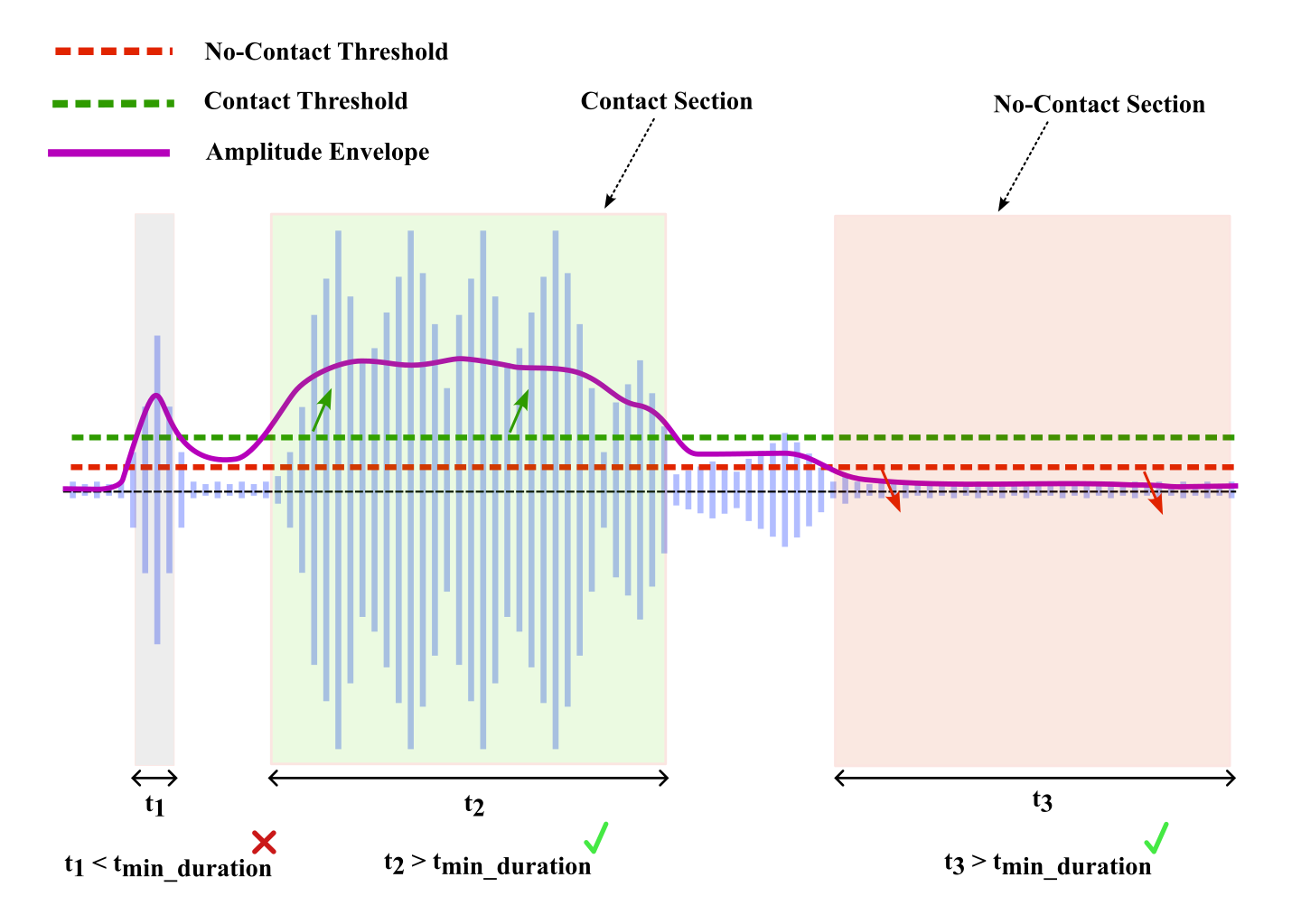
We automate annotation by computing a smoothed moving average of audio amplitudes and dynamically determining thresholds to separate contact from non-contact intervals. Segments shorter than 1 s are discarded, and gaps below a merge threshold are merged, producing high-quality labels without manual effort.
Key equations:
\[ T_{\rm dynamic} = F_{\rm noise} + (F_{\rm signal} - F_{\rm noise})\,\alpha_{\rm offset} \quad,\quad C(t) = \begin{cases} 1 & E(t)>T_{\rm dynamic}\\ 0 & E(t)\le T_{\rm dynamic} \end{cases} \]
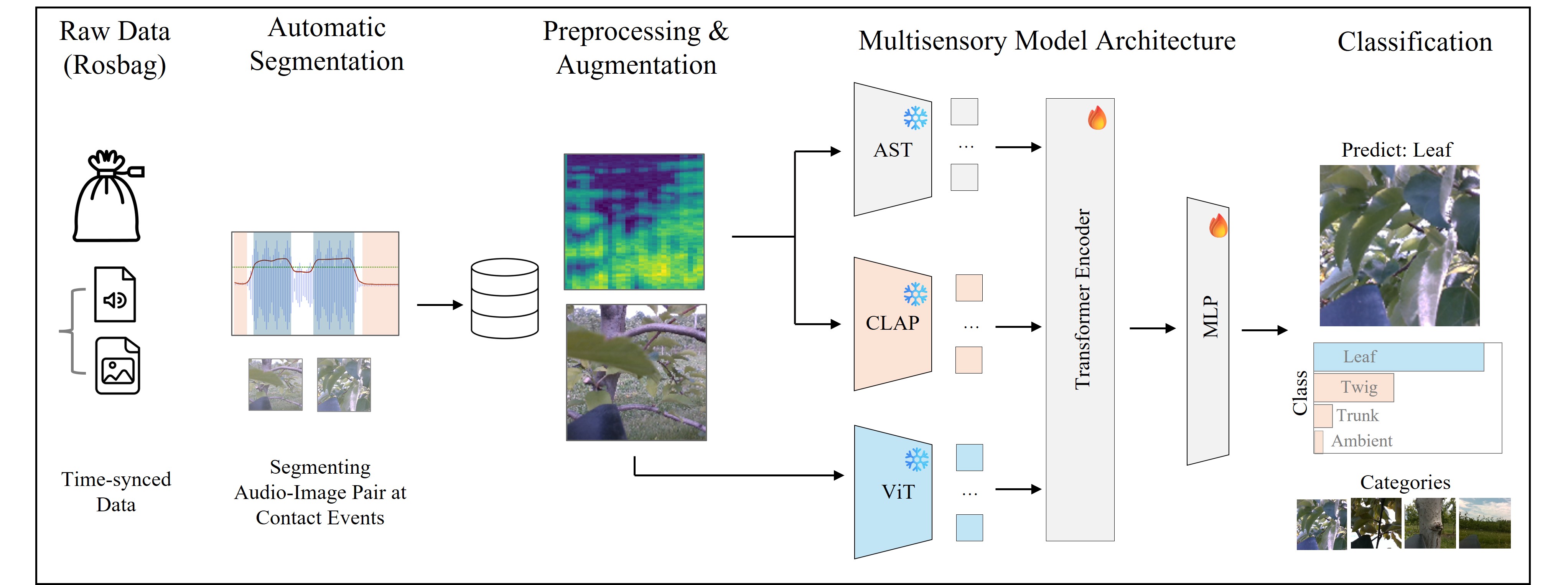
Our multimodal classifier encodes mel-spectrograms via an Audio Spectrogram Transformer (AST) and a CLAP encoder, and RGB images via a Vision Transformer (ViT). A self-attention transformer fuses these embeddings, followed by an MLP head for final contact-class predictions.
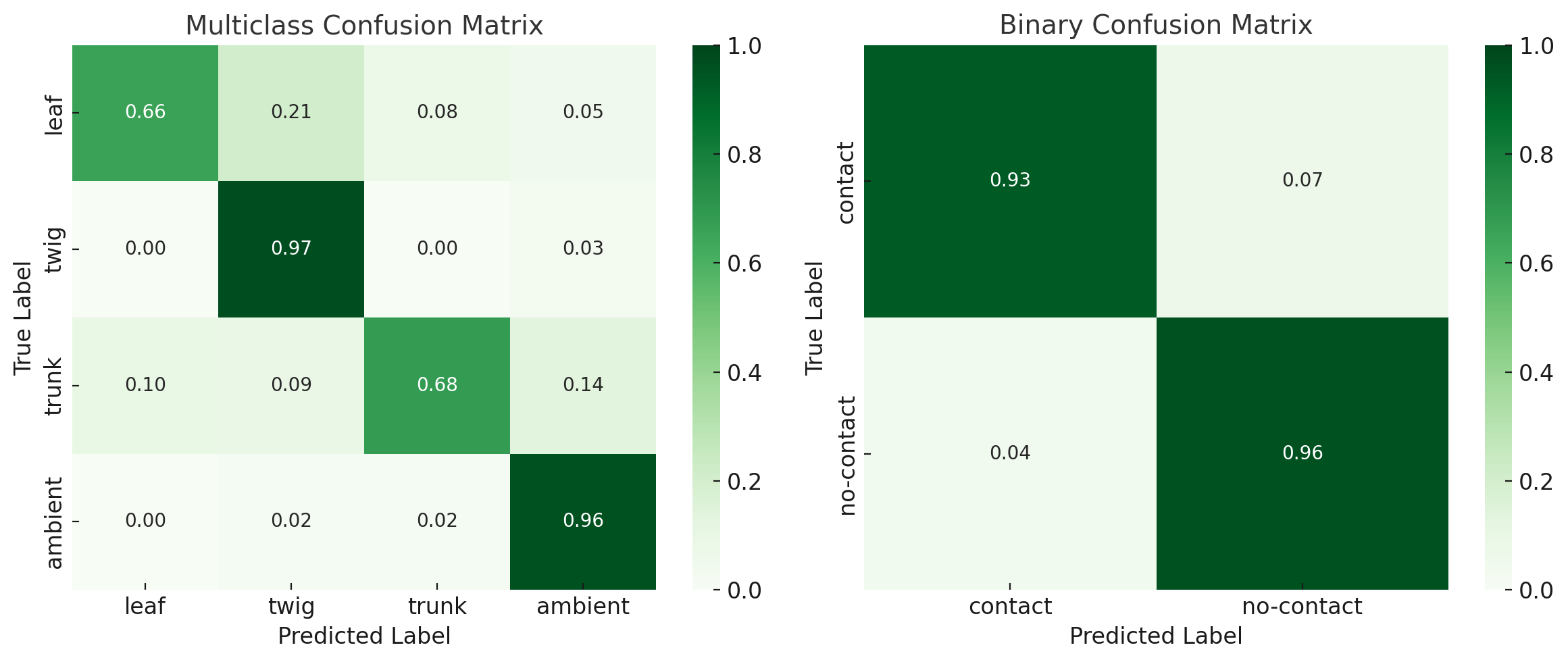
When trained on human probe data and tested on robot recordings, our fused audio-visual model achieves a multiclass F1-score of 0.82, outperforming audio-only (0.53) and image-only (0.55) baselines. Binary contact detection reaches F1 = 0.94.
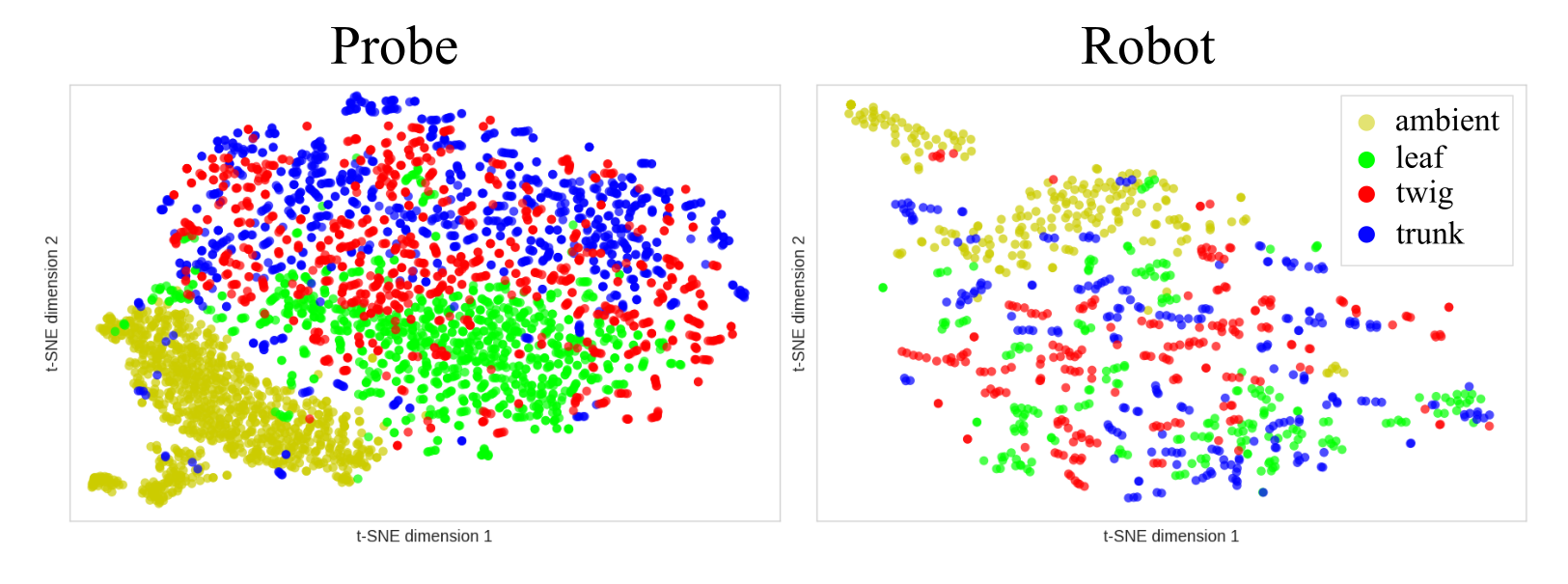
T-SNE projections of audio embeddings reveal clear separation of ambient vs. leaf, with some overlap between twig and trunk on probe data. Robot data clusters are less distinct, underscoring the need for multisensory fusion.
This work demonstrates that contact microphones, when paired with vision, significantly improve classification of tree contacts under real-world conditions. Future work will explore real-time planning integration and extension to other agricultural contexts.